
Insights
·
3 MIN
18 nov 2025
Qué son las AI Evals y por qué son tan relevantes ahora
Cada vez más empresas están construyendo productos basados en IA, pero pocas cuentan con una visión realmente precisa de si su modelo está funcionando como debería.
¿Responde tu modelo a los prompts con precisión? ¿Sigue instrucciones de forma consistente? ¿Mantiene estabilidad entre versiones? ¿Se degrada su rendimiento con el tiempo? ¿Respeta el tono y estilo definidos en los prompts?
Sin una evaluación estructurada, es prácticamente imposible responder a estas preguntas. Y aquí es donde entran las evaluaciones de IA.
¿Qué significa evaluar un modelo de IA?
Evaluar no es simplemente probar manualmente si “parece” que el modelo responde bien. Evaluar implica:
Definir qué queremos medir y por qué.
Establecer métricas, criterios de calidad y los datos necesarios.
Diseñar cómo visualizaremos los resultados, garantizando trazabilidad y una visión clara de la performance del modelo en el tiempo.
Muchos equipos aún testean su IA de forma manual, lo cual genera:
Resultados inconsistentes.
Cambios de modelo que rompen flujos previamente optimizados.
Falta de trazabilidad sobre la performance en el tiempo.
Ajustes de prompts que degradan la calidad sin que nadie lo note hasta demasiado tarde.
Si trabajas con IA, probablemente esto te resulte familiar.
AI Evals
Los evals o evaluaciones prueban sistemáticamente las salidas del modelo para validar que cumplen los criterios de contenido, estilo y funcionalidad que se especifiquen en los prompts.
Construir evals para entender cómo se comportan tus aplicaciones basadas en LLM —especialmente cuando actualizas o pruebas nuevos modelos— es un componente esencial para construir aplicaciones de IA confiables.
Cómo crear y ejecutar Evals con OpenAI
OpenAI incorpora la funcionalidad Datasets como una forma rápida y sencilla de crear evals y testear prompts. El flujo es simple:
1. Subes un CSV
Este dataset sirve como base para tus pruebas. Cada columna puede integrarse dinámicamente dentro del prompt.
2. Construyes un prompt
Desde el panel puedes crear distintos prompts que reutilizan el mismo dataset.
Ejemplo: si el dataset incluye la columna company, tu prompt podría ser:
“Genera un reporte financiero detallado sobre la empresa {{company}}”.
3. Generas y anotas outputs
Con los datos y el prompt configurados, puedes generar salidas del modelo para analizar cómo ejecuta la tarea.
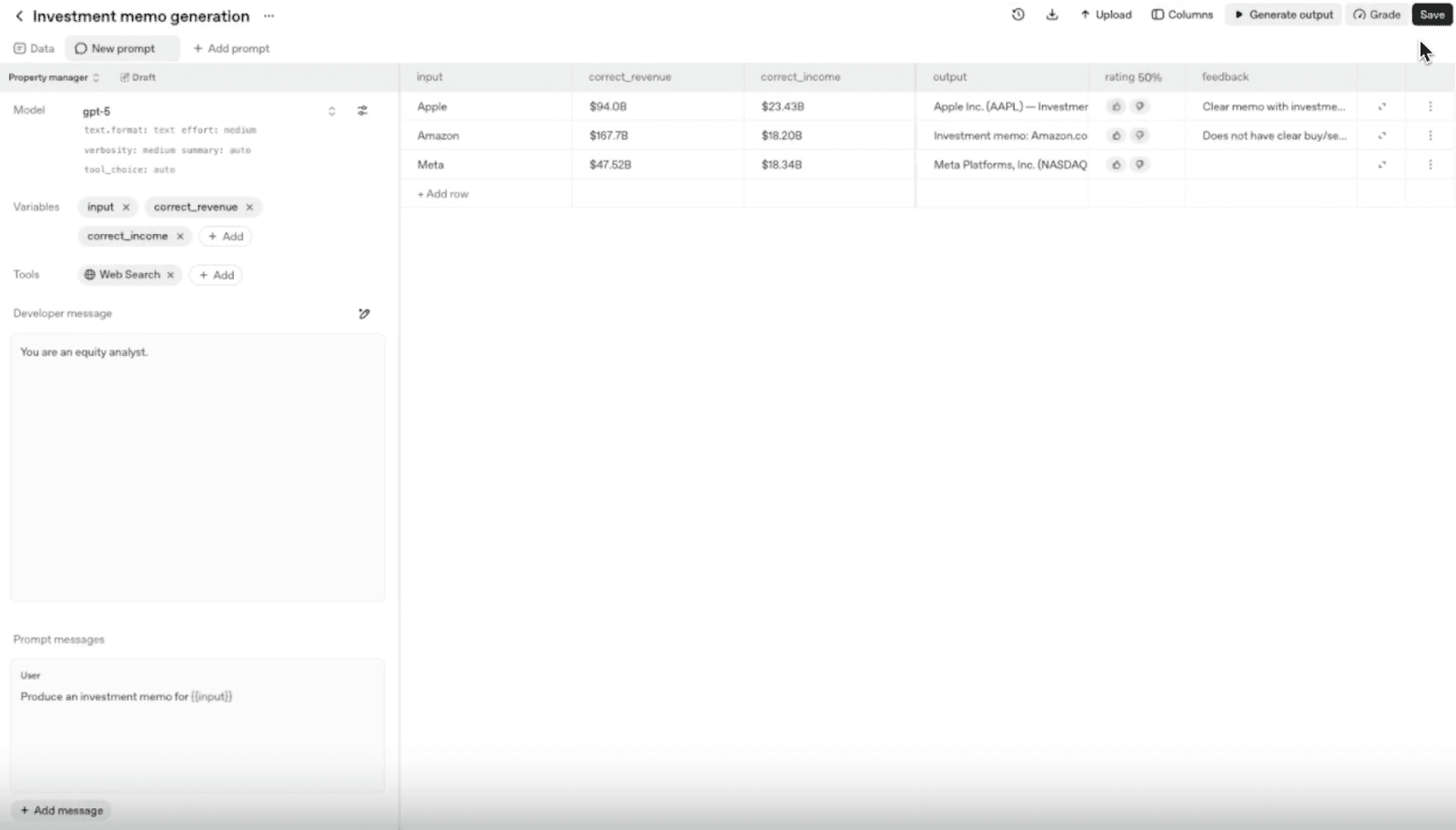
Después podrás anotar esos outputs para que el sistema pueda mejorar su rendimiento con el tiempo.
Las anotaciones son una parte fundamental para evaluar y mejorar las salidas del modelo. Una buena anotación:
Sirve como ground truth del comportamiento deseado del modelo, incluso en casos muy específicos—incluyendo elementos subjetivos, como el estilo y el tono.
Facilita el diagnóstico de deficiencias en el prompt, especialmente en casos poco frecuentes.
Ayuda a garantizar que los graders estén alineados con tu intención.
Puedes usar diferentes tipos de anotaciones:
Evaluación “Buena/Mala”, que indica tu valoración sobre la salida del modelo.
Comentarios detallados sobre cada una de las salidas del modelo.
Categorías personalizadas
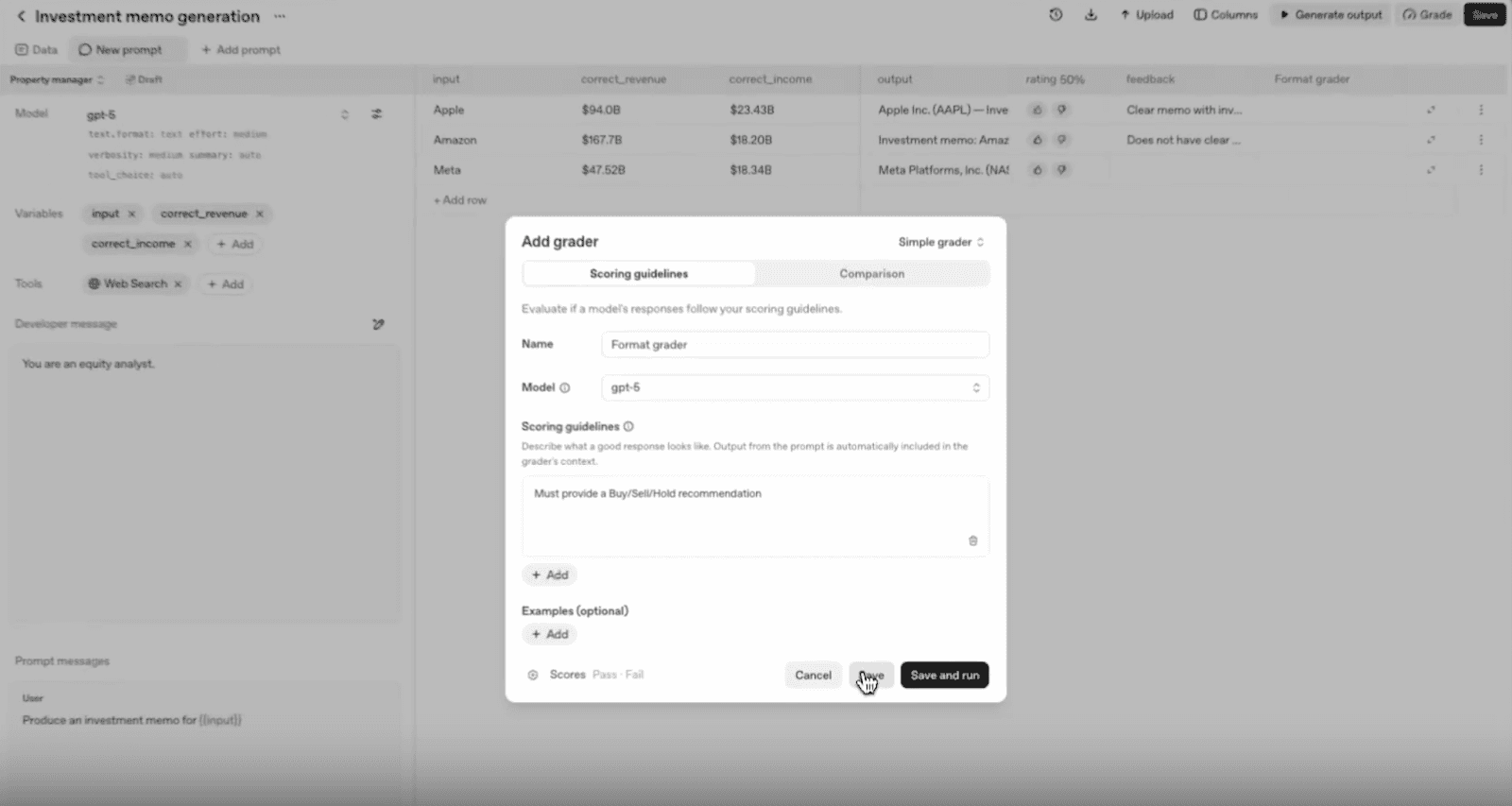
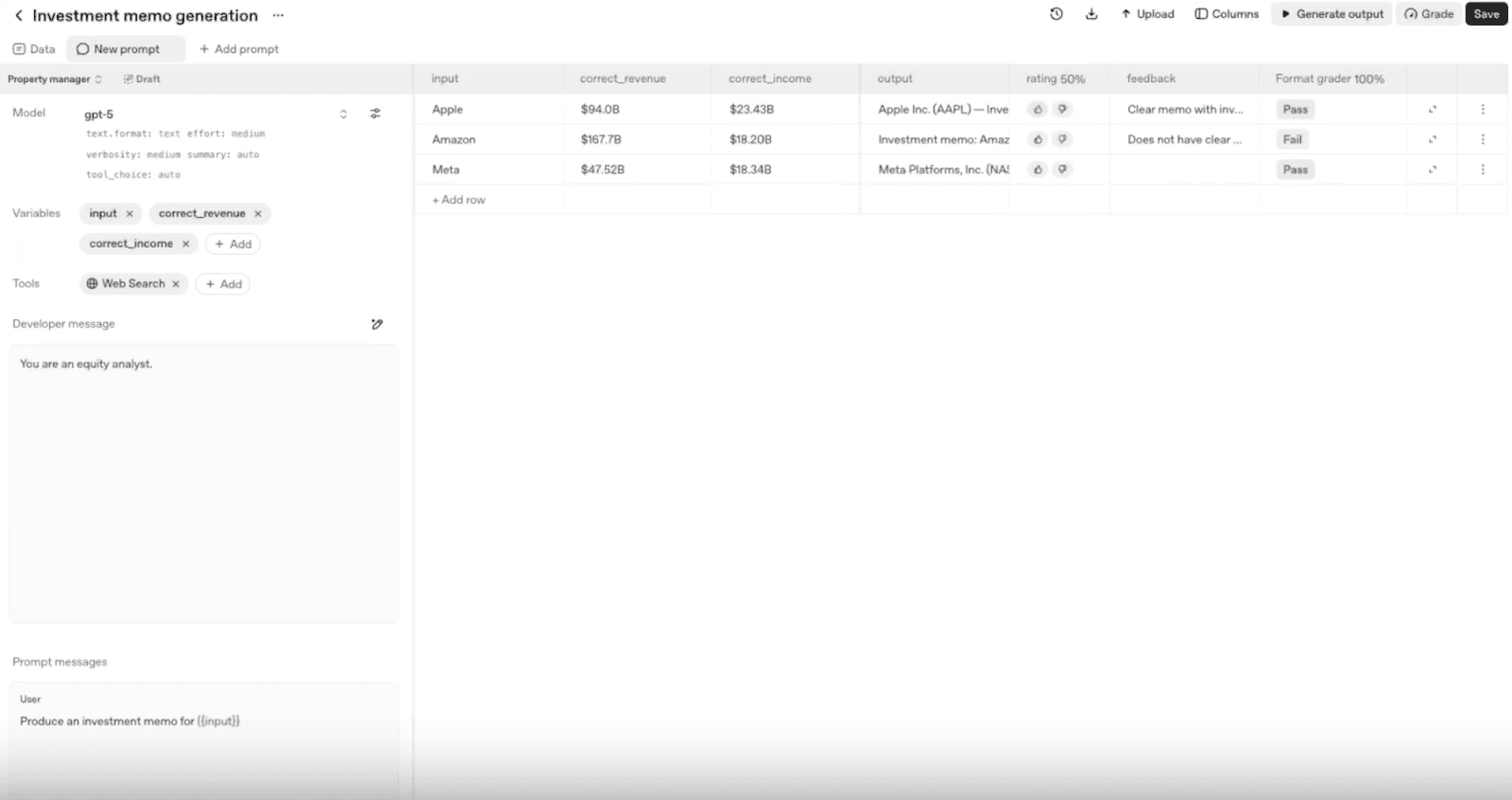
4. Añades graders
Los graders permiten evaluar el rendimiento de un modelo comparando sus respuestas con un conjunto de datos de referencia.
Aunque las anotaciones humanas son fundamentales, los graders automáticos permiten escalar el proceso de evaluación. Según su configuración, pueden evaluar:
Si el proceso de evaluación generado por el LLM se mantiene alineado con el proceso de etiquetado definido manualmente.
Si un nuevo prompt mejora o empeora resultados.
Si un cambio de modelo introduce regresiones.
Si cambios en parámetros del modelo generan mejoras.
Si nuevas casuísticas en los datos revelan fallas del prompt original.
Evals API
Para evaluaciones a gran escala, monitoreo continuo y comparación entre versiones, OpenAI ofrece la Evals API.
Con ella puedes:
Ejecutar evaluaciones de forma asíncrona.
Manejar grandes volúmenes de datos.
Detectar automáticamente regresiones entre prompts o modelos.
Construir un sistema de calidad continuo y automatizado.
Si estás construyendo productos de IA, las evaluaciones no son opcionales.
Las Evals te permiten:
Probar nuevos prompts antes de llevarlos a producción.
Validar si un cambio de modelo introduce regresiones.
Medir mejoras en precisión, estilo, tono, contenido o funcionalidad.
Ejecutar cientos de pruebas automáticamente.
Monitorear el rendimiento a lo largo del tiempo y entre versiones.
Entender de forma continua el comportamiento del modelo e identificar degradaciones.
El verdadero objetivo de las AI Evals es entender con precisión cómo se comporta tu modelo, dónde falla, dónde mejora y cómo hacerlo más confiable en cada iteración.
¿Estás evaluando ya tus modelos de IA de forma estructurada, o sigues dependiendo, sobre todo, de pruebas manuales?
¿Qué tipo de Evals has implementado ya y qué aprendizajes has obtenido sobre el comportamiento del modelo para facilitar una mejora continua?
——————————————
Este es el proceso en 6 pasos que utilizo yo para realizar Evaluaciones de IA, combinando evaluación humana y evaluación automática con LLMs. Un enfoque híbrido, escalable y orientado a producción.
1. Comienzo con un prompt muy básico; es solo el punto de partida. Más adelante, el análisis de las respuestas me proporciona información para mejorar tanto el prompt como el knowledge base que utilizan los LLM en sus respuestas.
2. Defino criterios claros de aceptación y un sistema de scoring para las respuestas de la IA (Bad, Average, Great).
3. Selecciono 25 inputs reales de usuarios y analizo la calidad de las respuestas del modelo de IA. Para cada criterio de aceptación definido (por ejemplo, tono, relevancia, etc), realizo una etiquetación manual y añado feedback cualitativo explicando por qué la respuesta es buena o no. Este proceso permite mejorar el prompt inicial y da lugar a la creación de un “golden dataset”, basado en evaluación humana (Human Eval).
4. Una vez creado el dataset inicial con etiquetas manuales, aplico una evaluación mediante LLMs (LLM as Judge Eval). El objetivo es validar que el LLM clasifica las respuestas de forma consistente con el proceso de etiquetado humano. Cuando esta validación es exitosa para cada criterio, la evaluación puede escalar de forma confiable.
5. A continuación, utilizo una muestra mayor (alrededor de 250 inputs de usuario) para analizar las respuestas del modelo. Si la calidad se mantiene estable en este volumen, continuamos escalando la solución.
6. Finalmente, producionalizamos la solución para un subconjunto reducido de usuarios mediante tests A/B y ejecutamos una evaluación continua (User Eval) de la calidad de las respuestas de la IA. Si la calidad de las respuestas cumple los criterios de aceptación definidos, la solución se escala de forma progresiva a un conjunto mayor de usuarios.
¿Cómo estás evaluando tú la calidad de las respuestas de tu sistema de IA?



