
Insights
·
2 MIN
19 jun 2026
Testing y monitorización de agentes: la capa que el mercado aún no ha resuelto.
Desplegar un agente en producción hoy sin una capa de test y monitorización es inaceptable.
Las soluciones de agentes aún están construyendo estas capas. Pocos casos de éxito. Mucho por resolver.
Las plataformas más relevantes estructuran su producto en cuatro capas:
Entrenamiento → Test → Despliegue → Análisis.
El problema: en la mayoría de soluciones actuales, el usuario puede revisar manualmente los resultados e identificar errores en el comportamiento del agente, pero no existe una capa de observabilidad ni un sistema de evaluación continua.
Eso genera dos limitaciones concretas:
→ Dificultad para evaluar y detectar degradaciones en la calidad de las respuestas.
→ Falta de visibilidad sobre regresiones tras cambios en prompts, modelos o fuentes de datos.
Tres compañías que sí lo han resuelto: Elevenlabs, Relevance AI y Fin.
Elevenlabs
Tests y Análisis: las dos funcionalidades para evaluar y monitorizar el comportamiento del agente en Elevenlabs.
La funcionalidad de Análisis opera en dos capas:
🔹 Evaluation Criteria. Define criterios de evaluación sobre conversaciones reales para saber si el agente resolvió correctamente cada interacción.
🔹 Data Collection. Extrae información estructurada de cada conversación (email, empresa, preguntas de cualificación) y la sincroniza con el CRM.
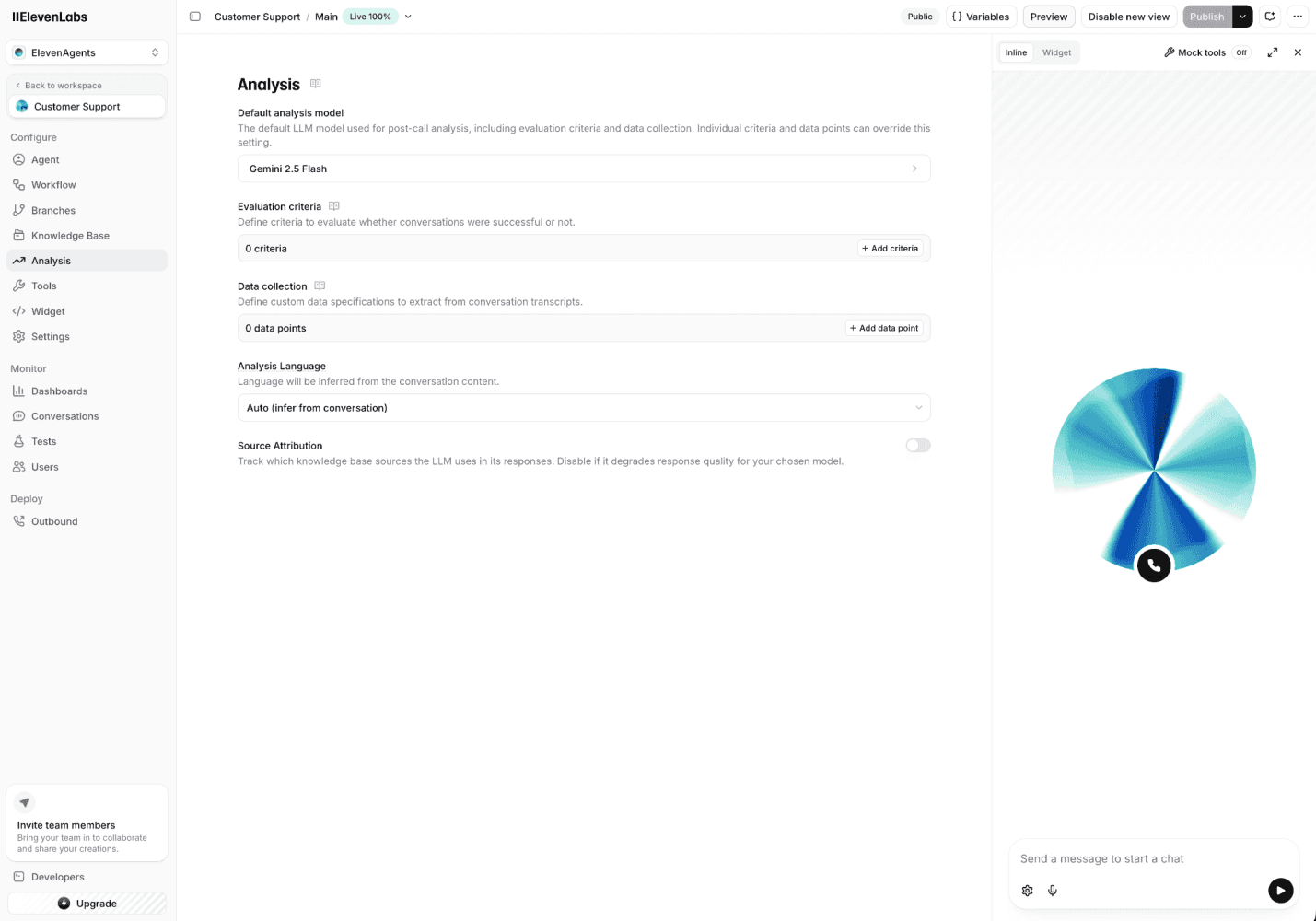
La funcionalidad de Test permite validar el comportamiento del agente antes del despliegue, un paso crítico en sistemas agénticos donde un error en producción tiene un coste reputacional. Incluye tres modalidades:
🔹 Scenario Testing. Valida que las respuestas del agente cumplen los criterios de calidad, tono y alineación con el negocio definidos previamente.
🔹 Tool Call Testing. Verifica que el agente invoca las herramientas correctas con los parámetros adecuados. Por ejemplo, que ante un "cancela mi pedido" ejecute la función correspondiente, con la integración del ecommerce y el identificador de pedido adecuados, o que ante un "quiero agendar una demo" lance la reserva con los datos correctos.
🔹 Simulation Testing. Conversación completa entre un usuario simulado por IA y el agente.
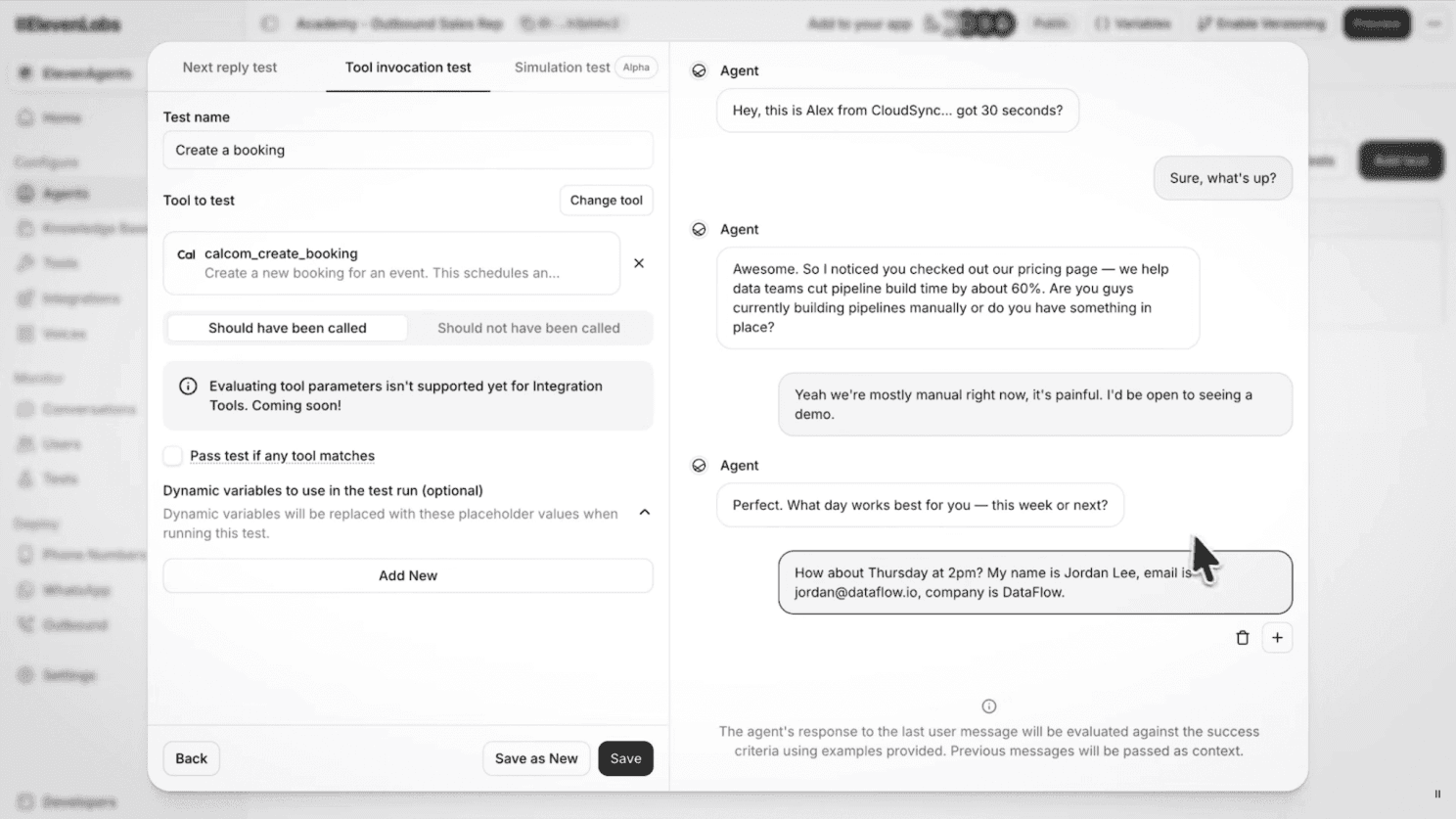
Estas simulaciones permiten anticipar cómo respondería el agente ante inputs específicos y detectar errores o regresiones antes de publicar cualquier cambio.
En definitiva: el Análisis audita los resultados en producción; el Test garantiza la calidad durante el desarrollo.
Relevance AI
Su plataforma incluye las siguientes funcionalidades para evaluación y testing de agentes de IA:
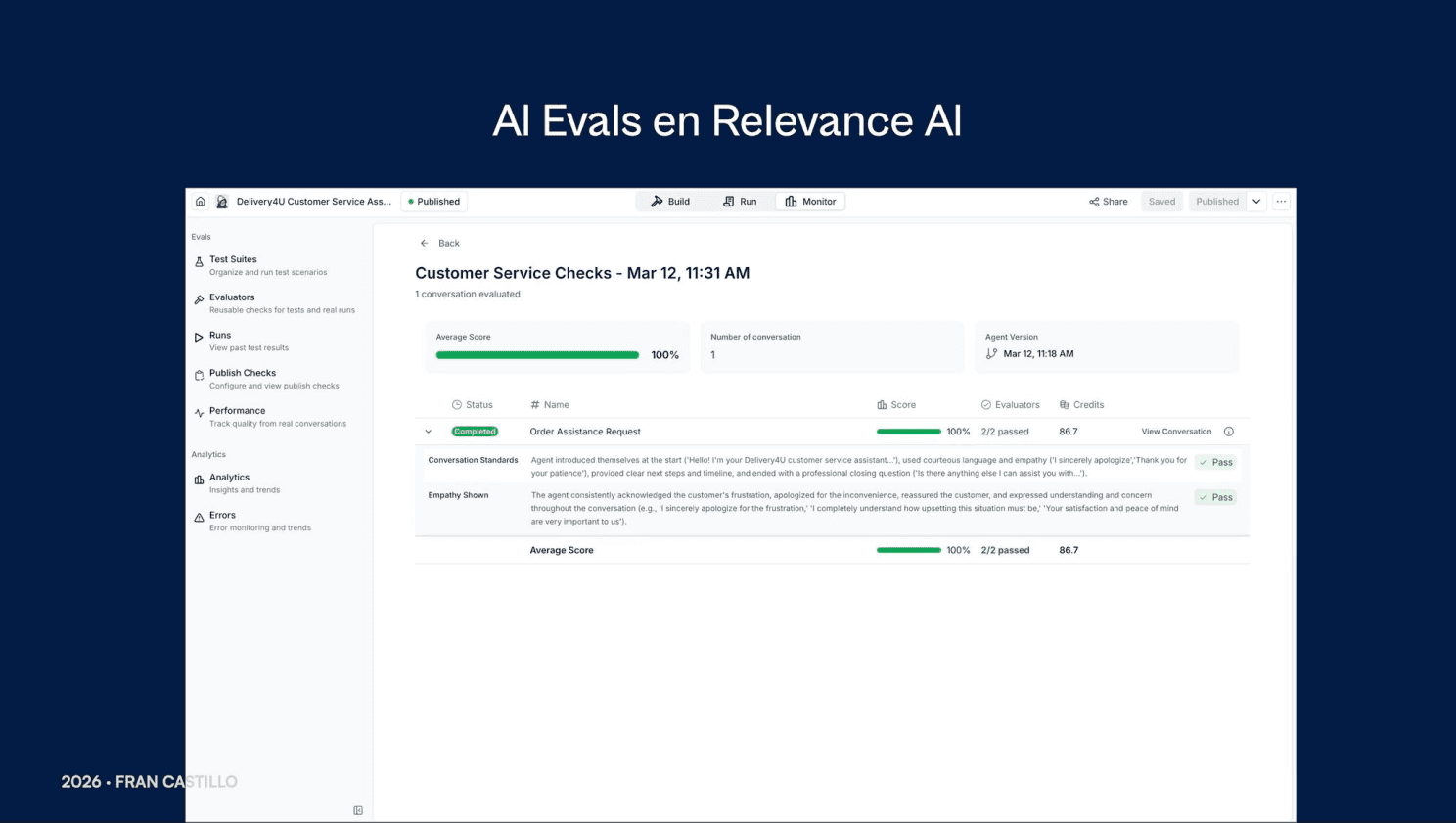
🔹 Test Suites. Crea escenarios que simulan conversaciones reales de usuarios con el agente. En cada uno puedes definir distintos criterios de evaluación y aceptación para medir la precisión y el rendimiento del agente.
🔹 Evaluadores reutilizables: LLM Judge, String Contains, String Equals y Tool Usage.
🔹 Runs. Consulta el historial de ejecuciones, de un Test Suite específico o de forma general, y accede a distintas métricas: puntuación media, número de conversaciones evaluadas, estado, créditos consumidos y fecha.
🔹 Performance. Monitoriza conversaciones reales en producción. Configura el umbral de aceptación en la evaluación para hacer seguimiento continuo de la calidad sin ejecutar Test Suites de forma manual.
🔹 Publish Checks. Define qué Test Suites deben superarse antes de publicar el agente. Establece un umbral mínimo y bloquea la publicación si la evaluación no lo alcanza.
Fin
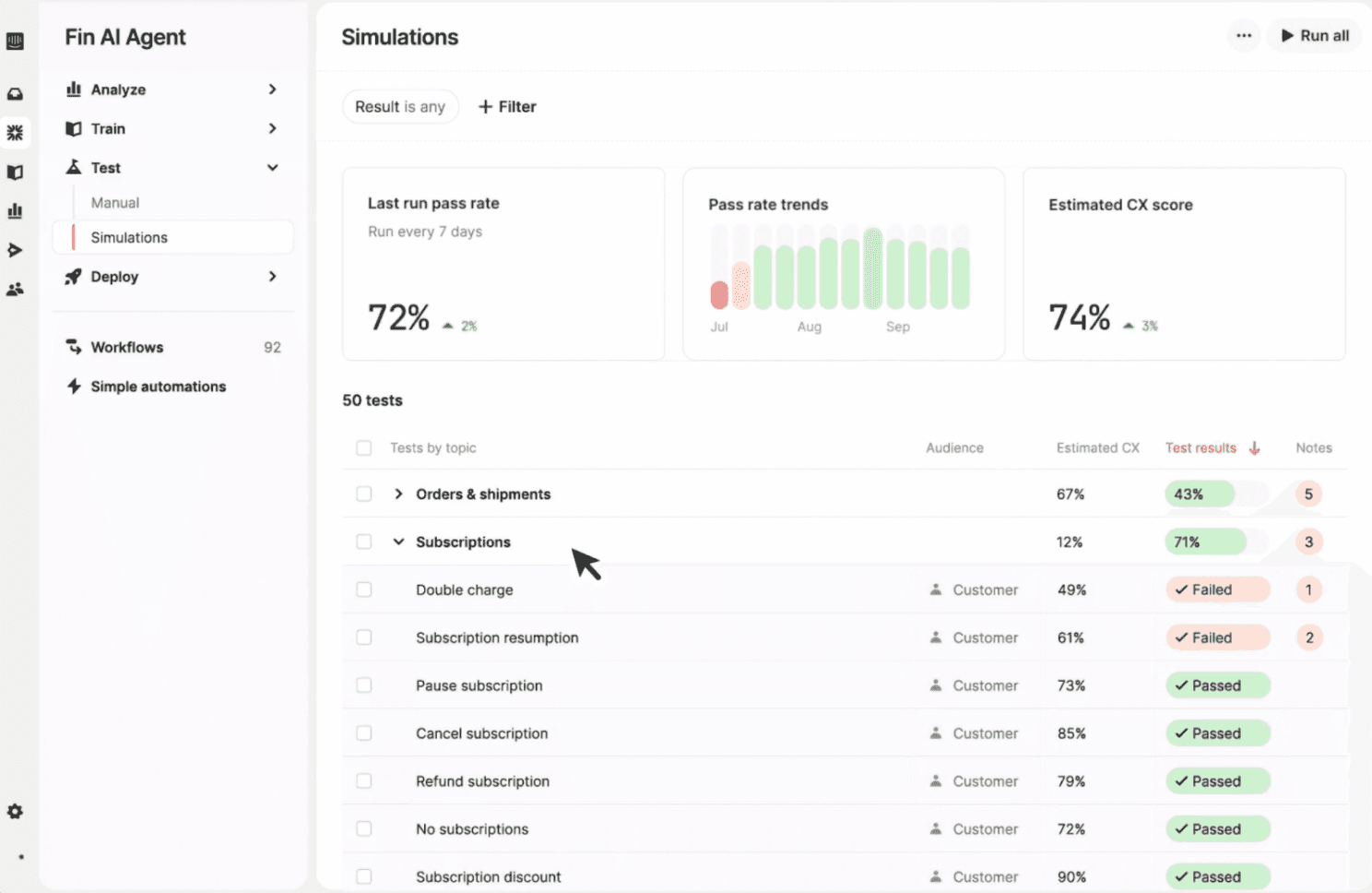
Su sistema de simulaciones permite testear agentes mediante conversaciones completas antes del despliegue:

🔹 Simulación completa de conversaciones. Se simulan conversaciones de principio a fin para observar cómo responde el agente en distintos escenarios, qué decisiones toma el agente y en qué puntos falla o tiene éxito.
🔹 La IA ayuda a generar nuevos tests, corregir los que fallan e iterar de forma continua basado en el feedback generado.
🔹 Librería de simulaciones. El agente incluye una librería de simulaciones que pueden reutilizarse para hacer evaluaciones. Cuando cambia alguna política o datos, los tests se vuelven a ejecutar para detectar regresiones antes de desplegar a producción.
El flujo completo de un agente bien construido queda así:
Construyes una versión inicial de la Knowledge Base, provees contexto, y entrenas al agente → Defines un escenario → Configuras el evaluador → Ejecutas el test → Ves la evaluación con explicación detallada → Despliegas en producción → Monitorizas su comportamiento → Mejoras la Knowledge Base.
El testing y la monitorización no son una capa adicional del producto. Son la parte principal.
En experiencias agénticas, la confianza es el producto.



